Spark作为新兴的大数据处理技术受到业界和学术界的高度关注,出于兴趣和自己的学习需要,最近开始接触Spark编程,和Hadoop一样,Spark的”Hello,world”就是一个简单的WordCount,这里记录一下完整的实现过程。
环境说明
配置Java,Scala,下载Spark安装包,解压到相应路径下。本例子采用Java-1.6.0_45(64bit)和Scala-2.10.4,spark-1.1.0-bin-hadoop2.4。具体配置在此不做介绍。
建立工程
编写Spark应用要严格按照规定的目录结构来存放相应文件,建立目录结构如下:
编写代码
|
|
保存为SimpleApp.scala
编写编译配置
|
|
保存为simple.sbt。
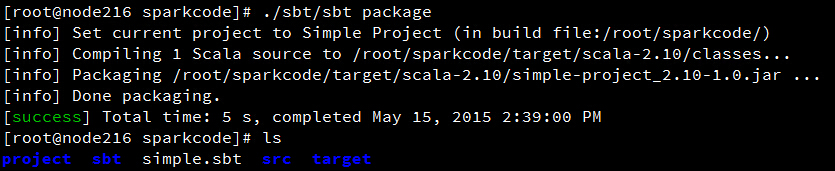
编译
使用sbt编译项目,自行下载sbt,将sbt目录放到项目文件夹下,编译命令:
编写执行脚本
为了方便提交执行,用脚本写下提交命令
保存为run.sh,chmod +x run.sh,放在项目主目录下。这里的local[2]是指的在本地开启2个线程执行。
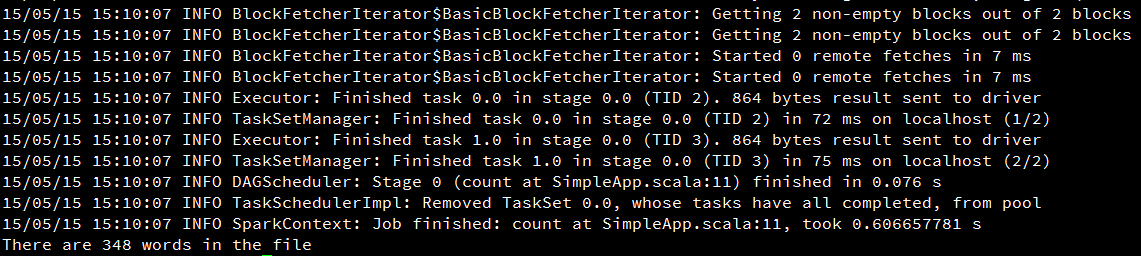
执行
在项目主目录下
用Intellij IDEA开发Spark App
开发Spark App还是用IDE比较方便,下面介绍如何使用IDEA写一个简单WordCount
新建项目
新建一个sbt项目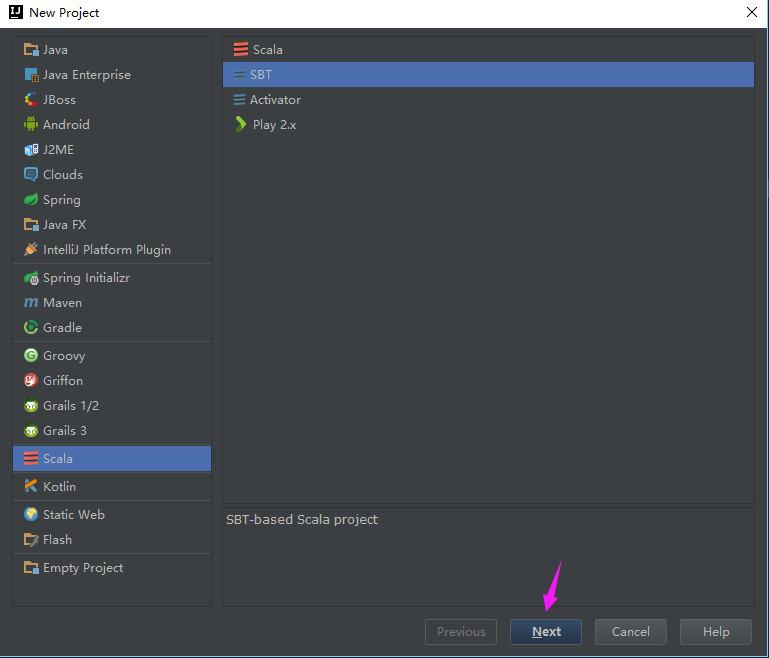
选择自动导入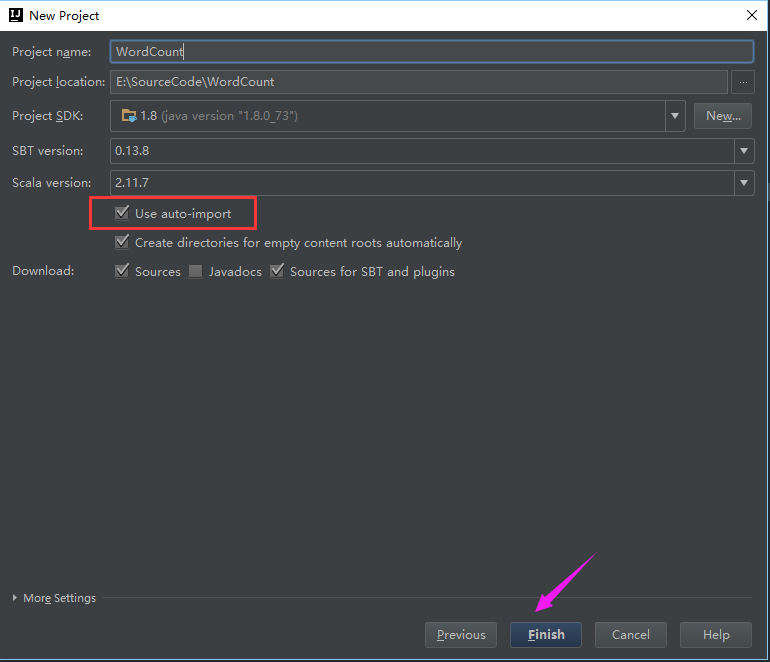
然后需要等待IDEA自动解决相关依赖,完成后项目结构如下: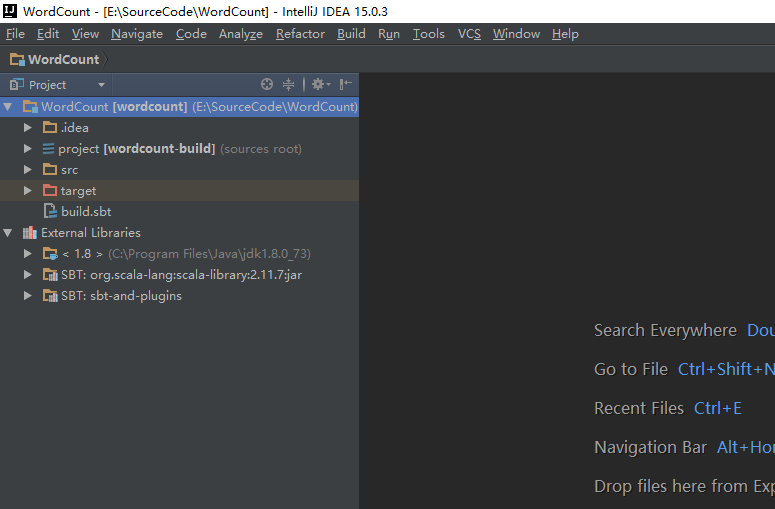
在项目下的build.sbt文件中加入依赖包说明
保存后IDEA会自动解析并下载相关包,完成后项目结构如下: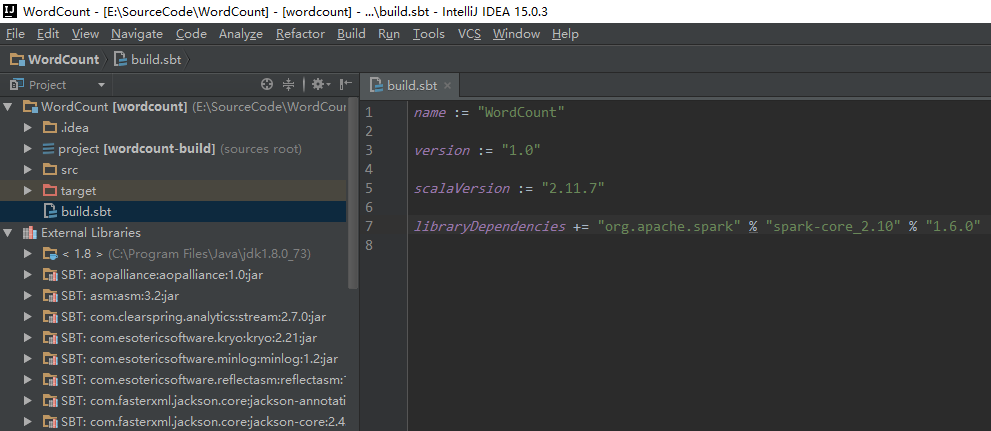
添加代码
在src/main/scala目录下创建新的object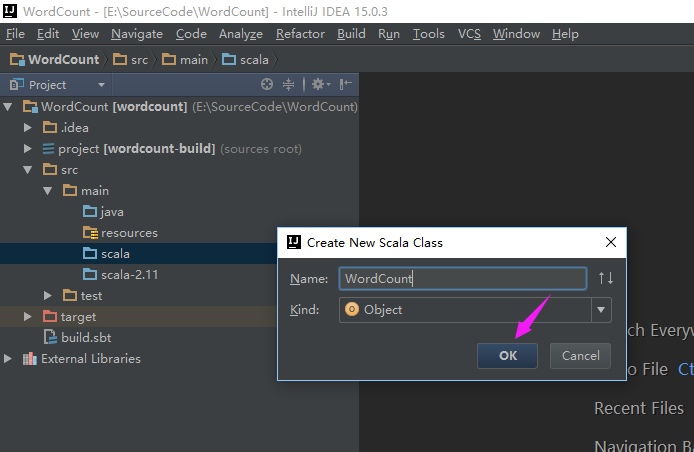
然后添加代码
编译
File->Project Structure->Artifacts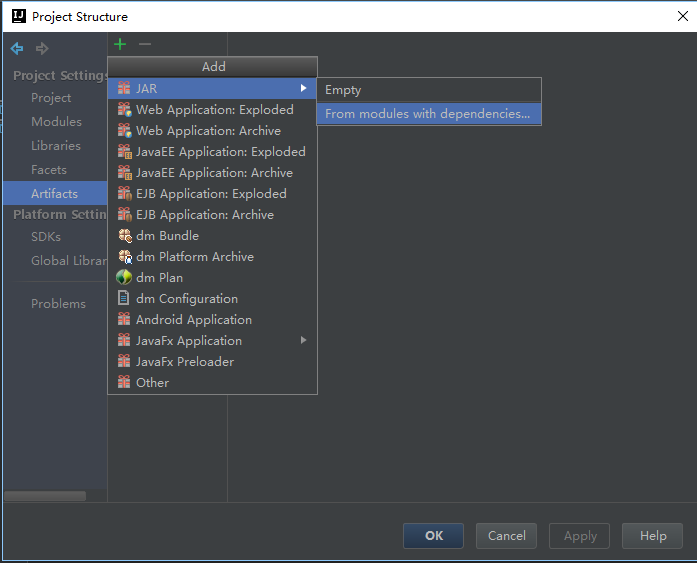
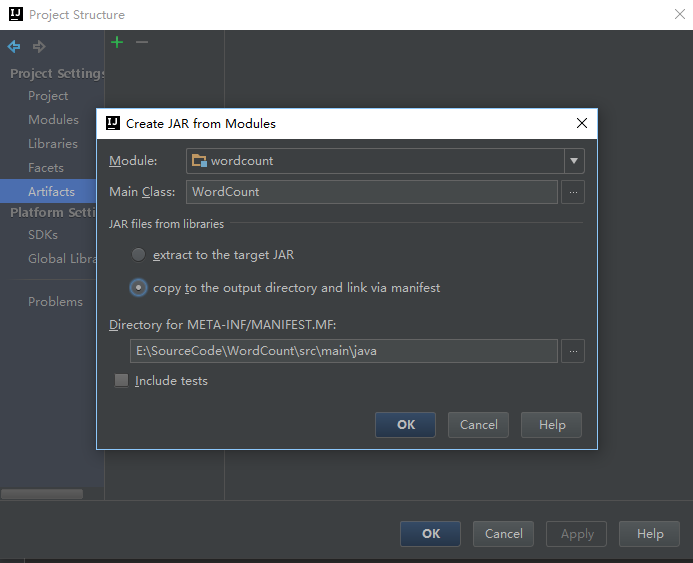
之后就开始编译,Build->Build Artifacts->build,片刻之后就可以编译成功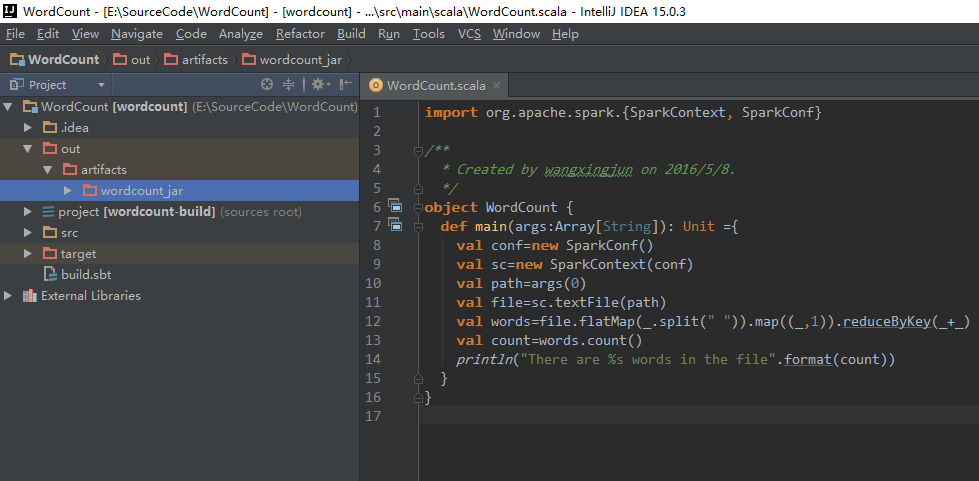
在wordcount.jar文件夹下就可以看到wordcount.jar包
运行
将编译好的wordcount.jar包上传运行即可