这篇文章将会完成Part 1中留下的部分,我会尽力介绍更多的你关心的能加速Spark程序的东西。特别是你将会学习资源调优或者配置Spark来充分利用集群提供的所有资源。然后我们会转向并行度调优,job性能中最难的也是最重要的参数。最后你会学习如何表示数据本身,Spark能读取的磁盘存储形式(用Apache Avro或者Apache Parquet)和视作缓存或者系统移动的内存存储形式。
资源分配调优
Spark用户列表经常被这样一类问题困扰:“我有一个500节点的集群,但是当我跑我的应用的时候我只看到两个task同时执行”。如果指定了Spark资源占用的参数,这些问题就不是问题了,但在这一节中你将会学习如何榨干你的集群最后一点资源。以下的建议和配置在不同Spark集群管理器(YARN,Mesos和Standalone)上会有所不同,但是我们仅仅只关注在YARN上,也是Cloudera推荐的方式。
要看一下Spark在YARN上跑的背景知识,可以去看这篇博客
在YARN上考虑的两个主要资源就是CPU和内存,磁盘和网络IO也会影响Spark性能,但是Spark和YARN目前都没有有效管理机制。
一个应用中每个Spark executor都有相同的固定数目的core和固定的heap size。core数可以在命令行调用spark-submit,spark-shell或者pyspark时通过—executor-memory指定,或者在spark-defaults.conf文件中或者SparkConf对象中设置spark.executor.cores参数。类似地,heap size也可以通过—executor-memory或者spark.executor.memory来控制。cores属性控制了一个executor可以并发执行的task数量,—executor-cores 5意味着每个executor最多可以同时执行5个task。内存属性指明了Spark可以缓存的数据量,同时也是用来group,aggregate和join的shuffle数据结构大小。
—num-executor命令行参数或者spark.executor.instances配置属性可以控制请求的executor个数。从CDH 5.4/Spark 1.3开始,你可以通过设置spark.dynamicAllocation.enabled属性打开动态资源分配来禁用这一属性。动态分配可以让Spark应用在有挂起的task时请求executor,而没有task时释放executor。
理解Spark资源请求如何映射到YARN中是很重要的,YARN相关属性是:
- yarn.nodemanager.resource.memory-mb
控制每个节点上的container使用的最大内存
- yarn.nodemanager.resource.cpu-vcores
控制每个节点上的container使用的最大core数目
请求5个executor core就相当于向YARN请求5个virtual core,YARN的内存请求稍微有点负责,原因如下:
- —executor-memory/spark.executor.memory
控制executor的heap size,但是JVM也能使用一些堆内存,比如字符串和直接字节的buffer缓存。spark.yarn.executor.memoryOverhead值被加到executor内存中用来决定每个executor使用的全部内存请求。默认是max(384, 0.07*spark.executor.memory)(注意,在Spark-1.6.1中0.07已经改成了0.1了,为了保证统一,后续也还是沿用0.07)
- YARN可能将请求的内存减小一点,YARN的yarn.scheduler.minimum-allocation-mb和yarn.scheduler.increment-allocation-mb属性分别控制最小值的和增量请求值。
下图(并非按比例)表示了Spark和YARN中的内存属性层次关系: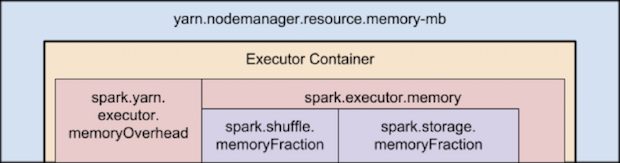
如果这还不足以用来理解的话,还有一些在设置Spark executor时最后需要考虑的:
application master是一个非executor的container,YARN中有一个特殊的请求机制,master必须使用它自己的资源预算。在yarn-client模式中,默认是1024 MB内存和1个vcore。在yarn-cluster模式中,master运行着driver,所以通常用—driver-memory和—driver-cores属性来设置比较有效。
给executor设置太多的内存经常会导致过高的GC(garbage collection,JVM的内存垃圾回收)延迟,单个executor的粗略内存上限是64GB。
我也注意到HDFS客户端经常受大量的并发线程所限制。每个executor上大概上限是5个task,这样就可以达到最大的write throughput,所以最好还是让每个executor上的core少于5个。
运行小的executor(比如一个core,运行单个task的内存量)就不能利用JVM多线程执行多个task的优势。比如每个executor上需要将广播变量复制一次,那么很多小的executor就会有大量数据副本。
为描述得更加具体一点,这里举一个例子来配置Spark app充分利用集群:设想有一个集群有6个节点运行NodeManager,每个节点配置16核,64GB内存。NodeManager容量,yarn.nodemanager.resource.memory-mb和yarn.nodemanager.resource.cpu-vcores就分别应该被设置成63*1024=64512(MB)和15。我们要避免将100%资源分配给YARN container,因为节点还要一些资源来运行操作系统和Hadoop的一些守护进程。在这种情况下,预留1个core和1GB内存给这些进程。Cloudera管理器可以帮你考虑并自动配置这些YARN属性。
冲动之下你很可能会使用—num-executor 6 —executor-core 15 —executor-memory 63G,然而这是一种错误的方法,原因如下:
- 63GB容量的Nodemanager不能满足63GB以上的executor内存开销
- application master会占用一个core和一个节点,这意味着那个节点上就没有空间容纳一个15-core的executor了
- 每个executor上15个core会导致严重的HDFS I/O吞吐
一个更好的选择就是用—num-executor 17 —executor-core 5 —executor-memory 19G,原因如下:
- 这种配置下除了有AM的节点有2个executor之外,每个节点上都有3个executor
- —executor-memory计算方式是(每个节点上63/3个executor)=21,21*0.07=1.47(之前说了至少留7%的内存给系统),21-1.47=19
并行度调优
众多周知Spark是一个并行处理引擎,一个不是很明显的特点就是Spark并不是一个完美的并行处理引擎,它找出最优并行度的能力有限。每个Spark stage都有一定数量的task,每个task都并行处理数据。在Spark Job调优过程中,这个数字恐怕是唯一一个决定性能的最重要的参数了。
那么这个数字是如何决定的呢?Spark如何划分RDD到stage中已经在上文述及。一个stage中的task数和对应哪个stage的最后一个RDD分区数相同。一个RDD的分区数和它所依赖的RDD分区数一样,除了coalesce转换可以允许创建比父RDD更少分区的RDD,还有union转换可以创建出父RDD们分区总数个分区的RDD,cartesian转换创建父RDD分区乘积个分区的RDD。
那没有父RDD的RDD是怎么样的呢?通过textFile或者hadoopFile操作产生的RDD分区数取决于底层MapReduce使用的输入格式。一般每个读入的HDFS分区都会成为一个RDD分区。通过parallelize产生的RDD分区数取决于用户给的参数,或者缺省的默认spark.default.parallelism
你可以随时用rdd.partitions().size()来确定一个RDD的分区数
主要应该关心的是task数量太少了。如果task数量比可用的slot数还少,那么这个stage就无法充分利用可用的CPU资源
少量的task意味着每个task中的aggregation操作的内存压力更大。任何join,cogroup,或者ByKey操作都会持有hashmap对象或者内存buffer来分组或者排序。join,cogroup,和groupByKey都在他们触发的shuffle拉取数据的一端的stage中使用这些数据结构。reduceByKey和aggreateByKey在shuffle两端的stage中都使用这些数据结构。
当内存容纳不下用来聚合操作的记录时,情况就会变得糟糕起来。首先,用这些数据结构保存大量的record会产生巨大的GC压力,这会导致执行暂停。第二,当内存不足以容纳record时,Spark会将records溢写到磁盘上,这样又会带来磁盘I/O和排序。这种在大规模shuffle中的开销是Cloudera用户中观察到job执行缓慢的最主要的因素。
那么你增加分区数量呢?如果问题中的stage是从Hadoop中服的,那你的选择有:
- 使用repartition转换,这会触发一次shuffle
- 配置你的输入格式,创建更多的数据分块
- 将HDFS输入数据写入块大小设置得小一些
如果当前stage从其他stage处获得输入,那么触发stage边界的转换将会接受一个numPartitions参数,比如:
那么X应该是多少呢?最简单直接的设置分区的办法就是试验:看一下父RDD的分区数,然后每次乘以1.5,直到性能停止增加为止。
也有一种比较正规的计算X的方式,但是因为一些参量难以计算出来所以无法做一个先验决策。在这里提及这个方法并不是建议大家平常去用它,而是为了帮助理解一些细节。我们最主要的目的就是执行足够多的task并保证每个task的内存刚好可以容纳下对应的数据。
每个task可用的memory是(spark.executor.memoryspark.shuffle.memoryFractionspark.shuffle.safetyFraction)/spark.executor.cores。内存占比和安全占比默认分别是0.2和0.8
内存中的shuffle数据大小很难确定。最方便的方式就是找出执行的stage中Shuffle Spill(Memory)和Shuffle Spill(Disk)之间的比例。然后将所有shuffle写数据量乘以这个比例。但是当stage在做一个reduction时就稍微有点复杂。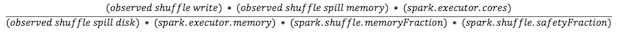
然后取一个约等于结果因为分区多一点通常比分区过少要好一些。
事实上,当举棋不定时,一般多一些task(相应分区也多一点)要好一点。这个建议是相对于MapReduce的,MapReduce中需要你对task数设置保守一些。根本的差别在于MapReduce中task的启动开销较大但Spark则不然(这是因为MapReduce是用的多进程方式,每个进程执行一个task,Spark采用的多线程方式,每个executor持有一个线程池,每个线程可以执行一个task)。
轻量化你的数据结构
数据是以record形式在Spark中流动的。一个record有两种表示方式:反序列化对象或者序列化二进制形式。通常来说Spark在内存中用序列化方式表示record,而在磁盘或者网络传输时用反序列化方式表示。已经有一些将内存中shuffle数据用序列化形式存储的计划工作了。
spark.serializer属性控制两种形式之间的序列化器。Kryo序列化器,org.apache.spark.serializer.KryoSerializer是首选项。但不幸的是它并不是默认采用的,因为Spark早期版本的Kryo的一些不稳定性并且不想破坏兼容性,但是大多时候应该用Kryo序列化器。
你的record在这两种形式之间的转换过程对Spark性能有很大的影响。仔细查看传输的数据类型并找出可以给其减重的地方通常是值得的。
过大的序列化对象会导致Spark经常将数据溢写到磁盘上,致使Spark可以缓存的反序列化对象数量减少(比如在MEMORY存储层)。Spark官方内存调优指南对此有很好的描述。除此之外过大的序列化对象会导致更大的磁盘和网络I/O开销,这里主要的方式是确保注册任何你自定义的类然后用Spark#registerKryoClassed API来传递。
数据格式
不管什么时候你需要决定如何在磁盘上存储你的数据,你都应该用一种可扩展的二进制格式,比如Avro,Parquat,Thrift或者Protobuf。选择其中一种并坚持使用之。说明一下,但谈及Hadoop上的Avro,Parquat,Thrift或者Protobuf的时候,都是指一个record在顺序文件中以Avro/Thrift/Protobuf结构存储。JSON文件不值得以这种方式存储。
每次你考虑用JSON存储大量数据时,在你花费大量的CPU cycle反复解析JSON文件时想想中东那边即将开始的冲突,加拿大那边严重污染的河流或者美国中部植物上的放射性沉降物(意思就是能耗高了呗)。另外你应该学习人际交往能力然后说服你的同事和上司也这么做。
结束语
所有内容到此结束,我从博客中学习到了很多有用的Spark编程知识,对整个应用的执行也有了较为清晰的了解,当然在此之前也应该好好阅读以下官方的文档。