本文针对Spark设计中shuffle部分进行详细介绍,是一篇大牛博客的译文,翻译外文博客只是为了记录自己阅读过程并存档方便随时回顾。
有人经常会问通常的shuflle到底是个怎样的过程?想象一下假设你有一个表单,上面有一串的电话通信记录详情,然后你想计算每天到底有几次通信。这种情况下你会把“day”作为你的key,然后对每条记录你就将1作为其值。之后你就将每个key的值加起来得到你要的结果,也就是每天的通信记录数。但是当你将数据存储在一个集群中,你又如何将分布在不同机器上的相同key的value相加呢?唯一的办法就是将所有相同key的value放在同一个机器上,然后你才可以像之前说的那样相加。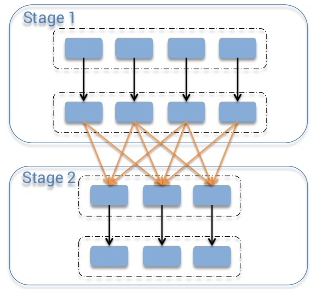
有很多task需要在集群中讲数据进行shuffle操作,比如table join—-将两个表单按照id域连接,你就必须保证两个表单中相同id的数据都存储在相同的数据块中。假设表的key在1到1000000之间。将数据存储在相同块的意思就是比如说两个表中key在1-100的记录都存储在单个的分区或者块中,这样就不需要对第一个表单的每个分区都去遍历第二个表单我们就可以将分区和分区合并,因为我们知道key在1-100的记录只存储在这两个分区中。为了达到这种效果两个表单要有相同数量的分区,这样就可以大大减少计算量。通过上述举例你可以知道shuffle是多么重要吧!
为了方便讨论这个主题,我依旧沿用MapReduce的命名规则。在shuffle操作中,从源executor发送数据的称作mapper,在目标executor中接受数据的task称作reducer,它们之间的操作就是shuffle。
一般来说shuffle有两个非常重要的压缩参数:
- spark.shuffle.compress 决定系统是否压缩shuffle的输出数据
- spark.shuffle.spill.compress 决定是否压缩shuffle临时溢写出来的文件
两个参数默认都是true,都用spark.io.compression.codec编码方式来压缩数据,默认是snappy。
你可能知道Spark中有多种shuffle实现方式,你用哪种实现方式取决于spark.shuffle.manager参数。3个可能的选择有:hash,sort,tungsten-sort,从Spark-1.2.0开始默认的shuffle方式都是sort。
Hash Shuffle
Spark-1.2.0之前默认的shuffle方式是hash(spark.shuffle.manager=hash),但是它有很多缺陷,主要因为其创建了大量文件,每个mapper task会为每个独立的reducer创建一个独立的文件,最终就会创建M*R个文件出来,M是mapper数,R是reducer数。在mapper和reducer较多的时候这会导致很严重的问题,输出的buffer大小,文件系统打开文件数和创建和删除文件的速度将会大受影响。有一个雅虎的例子可以参考,有46k个mapper和46k个reducer就会在集群中产生20亿个文件。
hash shuffler的实现逻辑相当简单粗暴:计算所有的reducer个数作为reduce端的分区个数,然后为每个分区创建一个独立文件,循环遍历需要输出的记录,然后计算出目标分区并将记录写到对应文件中,过程如下图: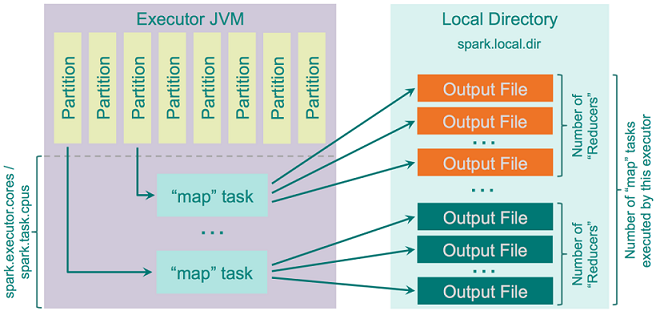
hash shuffler有一个优化参数spark.shuffle.consolidateFiles(默认false),当设置成true时,mapper的输出文件就会被合并。如果你的集群有E个executors(YARN上用—num-executor指定),每个executor有C个core(YARN上用spark.executor.cores或者—executor-cores指定),每个task用T个CPU(spark.task.cpus),那么集群中的execution slots数就是E*C/T,shuffle期间将会创建E*C/T*R个文件。如果有100个executor,每个executor有10个core,每个task对应1个core,有46k个reducer的话,通过合并操作可以将文件数从20亿减少到4600w,对性能将会有极大提升。这个特性实现方式很简单:它创建一个输出文件pool而非为每个reducer创建文件。当map task开始输出数据时,就会从这个pool中请求R个文件的分组。结束时就将这R个文件分组返还给pool。因为每个executor只会并行执行C/T个task,所以只会创建C/T个输出文件分组,每个分组有R个文件。在这C/T个task结束后,每个下一个map task都可以重用pool中已有的分组。下图是实现过程: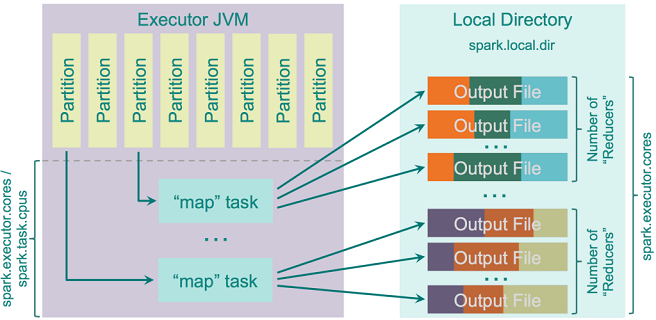
- 优点
- 快速—-因为不需要排序,也不需要维护hash table
- 数据排序没有内存开销
- 没有IO开销- 数据只写到HDD一次并读一次
- 缺点
- 当分区数较大,输出文件数较大会导致性能下降
- 向文件系统写入大量文件会导致IO随机IO的倾斜(也就是随机IO变多的意思),而通常随机IO比顺序IO要慢100倍
关于在单个文件系统百万级文件IO操作变慢可以参考这里
当然,当数据被写进文件时会被序列化或者压缩(可选),被读取时则刚好相反—-解压并反序列化。拉取数据一端的一个重要参数spark.reducer.maxSizeInFlight(默认是48M)决定每个reducer从远端executor请求的数据量。这个数据量是由来自不同executor上的5个并行请求平分,这样来加快这个过程。如果你增大这个数据量,你的reducer就会以更大的数据块来向map task输出请求数据,这样可以提升性能但同时也会增加reducer的内存开销。
如果reduce端不强制对记录排序,那reducer就只返回一个具有对map输出依赖关系的迭代器,但如果需要排序的话就需要将数据全部拉取过来并使用ExternalSorter进行排序。
Sort Shuffle
从Spark-1.2.0开始,sort shuffle被作为默认的shuffle算法(通过spark.shuffle.manager=sort开启)。大体上讲其实是尝试实现Hadoop MapReduce所使用的shuffle逻辑。hash shuffle中为每个reducer输出一个独立的文件,但sort shuffle中就更智能一点:每个输出的独立文件都根据reducer的id排序并索引,这样就可以通过获取相关数据块在文件中的位置信息,在读取之前做一个简单的fseek,很容易就可以拉取和reducer X相关联的数据块了。但显然reducer数较少时hash方式比sort方式要快,因此sort shuffle有一个退化机制:当reducer数少于spark.shuffle.sort.bypassMergeThreshold(默认200)时,就用将数据hash进多个独立文件然后将之合并到一个独立文件中,这一部分逻辑在一个独立类BypassMergeSortShufflerWriter中实现。
sort shuffle一个有意思的地方就是它在map端对数据排序,但是在reduce端不合并排序结果—-除非需要对数据排序才会对数据进行重排序。Clouderea有这方面的经验。他们开始实现对mapper输出先排序然后在reduce端合并,而不是重排序。你可能知道在Spark的reduce端排序是用TimSort,这是一个十分优异的排序算法,它利用了预先排序的输入。
但是当内存不足以存储map输出怎么办呢?这时候你可能需要将临时数据溢写到磁盘上,spark.shuffle.spill参数决定是否溢写,默认是开启的。如果你禁止了并且没有足够内存存储map输出,你就会收到OOM错误。
用来在溢写到磁盘之前存储map输出的内存大小为JVM Heap Size*spark.shuffle.memoryFraction*spark.shuffle.safetyFraction,默认是JVM Heap Size*0.2*0.8 = JVM Heap Size*0.16。你要知道如果你在同一个executor中跑很多线程(将spark.executor.cores/spark.task.cpus设置大于1),那么每个task存储map输出的内存大小就是JVM Heap Size * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction/spark.executor.cores * spark.task.cpus, 其他选项默认的话,2个core就有0.08 * JVM Heap Size。
Spark内部用AppendOnlyMap结构来在内存中存储map输出。有趣的是,Spark用自己的Scala实现hash table- 用quadratic probinghash并存储相同数组的key和value。采用了Google Guava库中的murmur3_32作为hash函数。
hash table允许Spark直接在table上应用combiner逻辑- 每个已有的key新加入的value都用已有的value来进行combine。combine的输出结果存为一个新的value。
当发生溢写的时候,会在存储在当前的ApppendOnlyMap中的数据上调用排序器对其进行TimSort,然后数据被写到磁盘上。
当发生溢写的时候或者再没有mapper输出时,排序后的输出就被写到磁盘上,即保证数据落盘。数据是否罗盘取决于OS的设置(比如文件buffer),但是它由OS决定,Spark只发送写指令。
每个溢写的文件都独立被写入磁盘,只有在数据被reducer请求并且要实时合并时才会进行合并操作,也就是说不会像Hadoop MapReduce中那样调用磁盘合并器,只是从独立溢写文件中动态收集数据并用Min Heap来合并。过程如下图: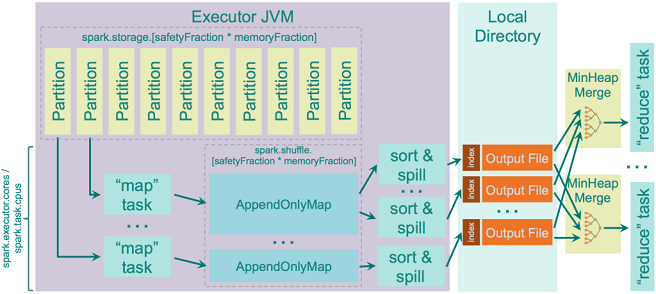
- 优点
- map端创建的文件数小一些
- 随机IO操作少一些,大部分是顺序读写
- 缺点
- 排序比hash慢,有时候可能要为你的集群调节一下bypassMergeThreshold参数来找到一个最佳配置,但通常大多数集群默认的参数都太大了
- 除非你用SSD来存储Spark shuffle临时数据,否则的话hash shuffle要更好一点。
Unsafe Shuflle or Tungsten Sort
Spark-1.4.0以上版本中Tungsten sort shuffle可以通过spark.shuffle.manager=tungsten-sort开启。其思想是基于Tungsten Project,很有创意。在shuffle中做的优化如下:
- 直接在序列化的二进制数据上操作,不再需要反序列化。它用了不安全(sun.misc.Unsafe)内存拷贝函数来直接拷贝数据,它可以更方便在序列化数据上操作,因为数据只是字节数组而已。
- 使用cache高效的ShuffleExternalSorter排序器来对压缩记录指针和分区id数组排序。通过在排序数组中每条记录使用8字节空间可以提升cache效率。
- 因为记录没有反序列化,溢写序列化数据可以直接操作。
- 当shuffle压缩编码方式支持序列化流级联时,自动使用额外的溢写合并优化。当前Spark的LZF序列化器支持,并且需要shuffle.unsafe.fastMergeEnabled被开启。
下一步的优化中,这个算法引入了off-heap storage buffer
只有当以下所有条件满足时才会使用这种shuffle实现:
- shuffle依赖中没有aggregation。aggregation意味着需要将数据反序列化存储然后才能将新来的value合并。这种情况下就无法利用这种shuffle直接操作序列化数据的优势
- shuffle序列化器支持序列化value的重定位(KryoSerializer和Spark SQL的自定义的serializer支持)
- shuffle产生的输出分区个数少于16777216
- 单个序列化记录不超过128M
同时要知道这种shuffle中只根据分区id进行排序,意味着用合并在reduce端预先排序的数据的优化和TimSort利用预排序数据的优势将会不复存在。这个操作中的排序是基于8-byte value的,每个value都对指向序列化数据的link和分区数进行编码,这就是为什么对输出分区个数限制在16777216的原因。
具体实现过程如下图: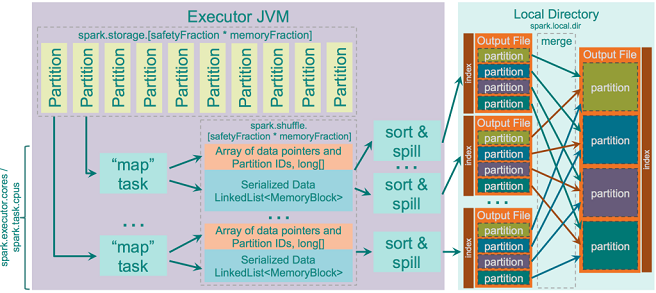
每个溢写的数据块首先将描述指针数组排序然后输出一个索引的分区文件,然后将这些分区合并到一个索引的输出文件中。
- 优点
- 性能提升
- 缺点
- 目前不能处理mapper端的数据排序
- 目前不能提供off-heap排序buffer
- 目前不稳定