Spark-1.6以后RPC默认使用Netty替代Akka,在Netty上加了一层封装,为实现对Spark的定制开发,必须对RPC实现方式有比较清晰的了解,本文解读Spark RPC实现。本文代码全部出自于Spark-2.0.0。
背景介绍
Akka是一个异步的消息框架,所谓的异步,简言之就是消息发送方发送出消息,不用阻塞等待结果,接收方处理完返回结果即可。Akka支持百万级的消息传递,特别适合复杂的大规模分布式系统。Akka基于Actor模型,提供用于创建可扩展,弹性,快速响应的应用程序的平台。Actor封装了状态和行为的对象,不同的Actor之间可通过消息交换实现通信,每个Actor都有自己的消息收件箱。Akka可以简化并发场景下的开发,其异步,高性能的事件驱动模型,轻量级的事件处理可大大方便用于开发复杂的分布式系统。早期Spark大量采用Akka作为RPC。Netty也是一个知名的高性能,异步消息框架,Spark早期便使用它解决大文件传输问题,用来克服Akka的短板。根据社区的说法,因为很多Spark用户饱受Akka复杂依赖关系的困扰,所以后来干脆就直接用Netty代替了Akka。因为Akka和Netty基础知识不是本文的重点,相关知识可自行查阅。
Spark-1.6+中的RPC
Spark-1.6以前的版本中RPC是采用Akka实现,我们以master和worker之间的通信为例解释Akka RPC的工作模式。Spark-1.6以后,RPC默认采用Netty实现。RpcEndpoint注册到RpcEnv上然后才能接收消息,RpcEnv处理从RpcEndpointRef或者其他远程节点的消息,然后回发给相应的RpcEndpoint。Rpc组件之间的关系见下图: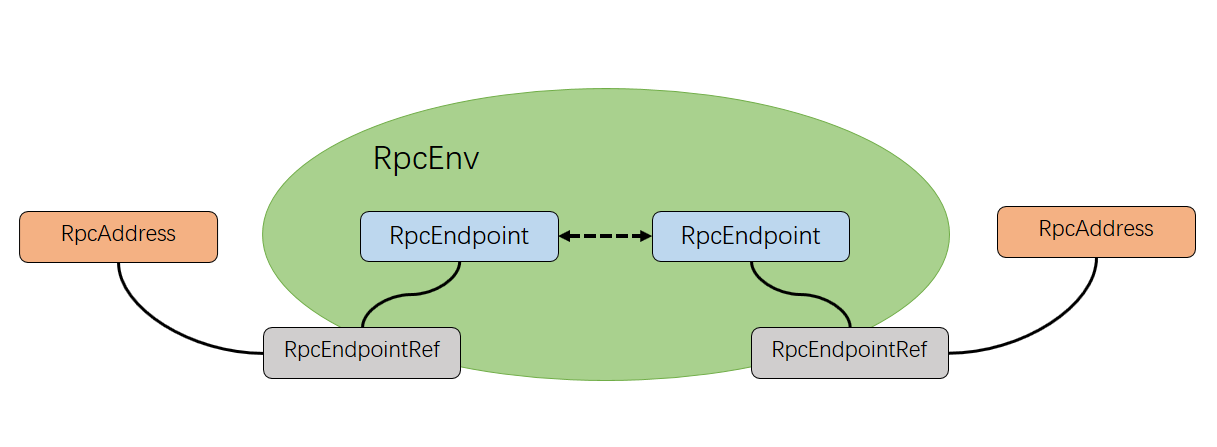
master实现
master的定义
我们看master类的定义
可以看到master类继承自ThreadSafeRpcEndpoint,进一步定位可以发现ThreadSafeRpcEndpoint是继承自RpcEndpoint特质。
master启动
再看master的启动方法:
RpcEndpoint特质
master的启动会创建一个RpcEnv并将自己注册到其中。继续看RpcEndpoint特质的定义:
RpcEnv抽象类
我们来看看RpcEnv的具体内容:
另外RpcEnv有一个伴生对象,实现了create方法:
这就是在master启动方法中的create具体实现,可以看到调用了Netty工厂方法NettyRpcEnvFactory,该方法是对Netty的具体封装。
master中消息处理
上文可以看到,在RpcEndpoint中最核心的便是receive和receiveAndReply方法,定义了消息处理的核心逻辑,master中也有相应的实现:
这里定义了master一系列的消息处理逻辑,而receiveAndReply中,
定义了对需要回复的消息组的处理逻辑。
worker实现
worker的定义
我们看看worker类的定义:
和master同样继承自ThreadSafeRpcEndpoint特质,也是一个Endpoint类型。
worker启动方法
有了前面master的分析,按照相同的逻辑,我们直接看worker的启动:
自然而然的,和master启动方法基本如出一辙,但是问题出在,worker是如何和master建立联系的?其实细心一点你就可以发现,在master消息处理中,receiveAndReply方法第一个处理的消息便是RegisterWorker,也就是处理来自worker的注册消息,那么事情就变得简单了,worker是通过将自己注册到master的RpcEnv中,然后实现通信的。
worker注册到master RpcEnv
定位到worker中发送RegisterWorker消息到master Endpoint的方法:
其中,masterEndpoint.ask是核心,发送了一个RegisterWorker消息到masterEndpoint并期待对方的RegisterWorkerResponse,对response做出相应的处理。这样worker就成功和master建立了连接,它们之间可以互相发送消息进行通信。ps:其实worker注册到master的步骤有一点复杂,涉及到容错等问题,具体的实现这里暂时不做讨论。
worker到master的通信
worker和master之间是一个主从关系,worker注册到master之后,master就可以通过消息传递实现对worker的管理,在worker中有一个方法:
一目了然,就是干的发送消息到master的活儿,在worker中很多地方都用到这个方法,比如handleExecutorStateChanged(executorStateChanged: ExecutorStateChanged)方法中,sendToMaster(executorStateChanged)就向masterRef发送了executorStateChanged消息,前文中master中的recevie方法中,就有一个对ExecutorStateChanged消息的处理逻辑。
master到worker的通信
同样的,master要对worker实现管理也是通过发送消息实现的,比如launchExecutor(worker: WorkerInfo, exec: ExecutorDesc)方法中:
master向worker发送了LaunchExecutor消息告诉worker应该启动executor了,而worker中的receive方法中对LaunchExecutor消息进行处理并完成master交代给自己的任务。
小结
复杂的分布式系统中RPC是最重要的一个模块,得益于前人的工作,Akka亦或Netty都为我们提供了完备的RPC实现框架。通过这些框架,我们可以不必去关心RPC实现方式,设计出复杂的分布式系统。本文只是本人在Spark学习过程中的一个记录,分布式系统远远不止这么简单,学习之路依旧漫长。