从1.6.0开始,Spark内存管理模式就变了,旧的内存管理模式通过一个StaticMemoryManager类实现,现在被称作legacy。legacy模式默认是关闭的,这就意味着相同的代码在1.5.x版本和1.6.0版本中执行会有不同,应该当心这点。出于兼容性考虑,你可以通过spark.memory.useLegacyMode参数来开启legacy模式,默认情况下是关闭的。
本文描述一个从1.6.0版本引入的新的Spark内存管理模式,详细代码在UnitedMemoryManager中实现。
简而言之,新的内存管理模式如下图: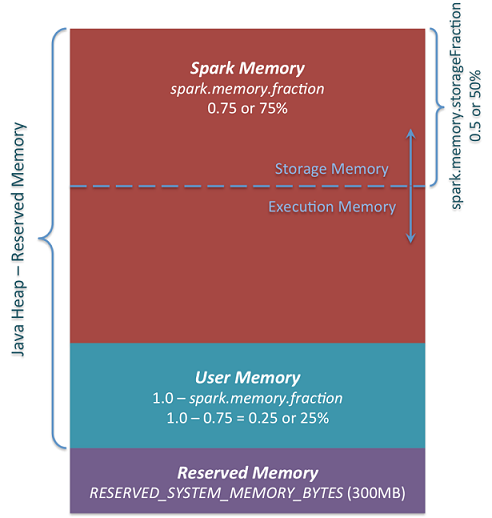
图中可以看出有3个主要的内存分区
Reserved Memory 这一块是系统预留的内存,其大小的硬编码的。在Spark-1.6.0中大小为300MB,这意味着这300M内存是不计入Spark内存区域大小的,并且除非重新编译Spark或者设置spark.testing.reservedMemory参数,这块内存大小是无法更改的。但是官方仅仅只是将之作为测试用,并不推荐在生产环境中更改。记住这块内存仅仅只是被称作“reserved”,事实上任何情况下都不能被Spark使用,但是它确定了Spark可以使用的内存分配上限。即使你想将所有的Java Heap给Spark来缓存数据,reserved部分要保持空闲所以你没法这样做(其实并不是真的空闲,里面会存储很多Spark内部对象)。如果你不给Spark executor设置1.5*Reserved Memory=450M,应用将会因为please use larger heap size而失败。
User Memory 这一块内存池是在Spark Memory之后分配,它的使用方式完全取决于你。你可以存储你用来转换数据的数据结构。比如你可以用mapPartition转换管理hash table来做aggreagtion这种方式重写Spark aggregation,这就会用User Memory。在Spark-1.6.0中这块内存大小可以通过(Java Heap - Reserved Memory) * (1.0 - spark.memory.fraction)来计算,默认是(Java Heap - 300M) * 0.25。比如4G的Heap大小,你就会有949M的User Memory。再次说明一下,这一块内存是User Memory,存什么和怎么存都取决于你,Spark不会管你在这里干什么和是否忽略分界。代码中忽略分界可能会导致OOM(out of memory)错误。
Spark Memory 最后Apache Spark还管理着一块Spark Memory,它的大小可以通过(Java Heap – Reserved Memory) * spark.memory.fraction计算,Spark-1.6.0中默认是(Java Heap - 300M) * 0.75。比如你有4G的Heap那么就会有2847M的Spark Memory。这一整块内存池被分为2个区域—-Storage Memory和Execution Memory,他们之间的分界是由spark.memory.storageFraction参数决定,默认是0.5。新的内存管理方式的优点就在于这个分界线不是固定的,根据内存压力这个分界线是可变的。比如说一个区域会占用另一个区域的内存而变大。下文将会讨论分界线如何变化,先看看这块内存如何使用的:
Storage Memory 这一块内存用作Spark缓存数据和序列化数据”unroll”临时空间。此外所有的”broadcast”广播变量都以缓存块存在这里。感兴趣的话unroll代码在这里。你可能会看到其实并不需要足够的空间来存unrolled块- 如果没有足够的内存放下所有的unrolled分区,如果设置的持久化level允许的话,Spark将会把它直接放进磁盘。所有的broadcast变量都用MEMORY_AND_DISK持久化level缓存。
Execution Memory 这一块内存是用来存储Spark task执行需要的对象。比如用来存储Map阶段的shuffle临时buffer,此外还用来存储hash合并用到的hash table。当没有足够可用内存时,这块内存同样可以溢写到磁盘,但是这块内存不能被其他线程(tasks)强行清除。
然后我们看看Storage Memory和Execution Memory之间分界是如何变化的。由于Execution Memory的特点,你无法从这块内存池中清除出内存块,因为这里的数据是用来做临时计算的,需要用到这里的内存的进程找不到相关的内存块就会执行失败。但Storage Memory则不然- 它仅仅是存储在RAM中的缓存块,如果我们从其中清除出内存块我们就可以更新块的元数据,也就是这个内存块被清除到了HDD(或者说简单地移出),然后读这个块时就会从HDD中读(如果持久化level不允许溢写到HDD的话,就重新计算)。
因此可以看到,我们可以从Storage Memory中清除出内存块,但Execution Memory则不行。那么Execution Memory内存池何时可以从Storage Memory中借取内存?有以下两种情况:
- Storage Memory中有空闲的空间,比如说缓存块没有将所有空间用尽。然后就会减少Storage Memory,增加Execution Memory。
- 当Storage Memory超出了初始的分区大小并用完了所有空间,这种情况会导致从Storage Memory中借取空间,除非它达到了初始大小。
反过来,只有在Execution Memory有空闲空间时Storage Memory才可以从Execution Memory借取一些空间。
初始的Storage Memory分区大小是通过Spark Memory * spark.memory.storageFraction = (Java Heap - Reserved Memory)* spark.memory.fraction * spark.memory.storageFraction,默认大小是(Java Heap - 300M) * 0.75 * 0.5 = (Java Heap - 300M) * 0.375。比如Heap有4G,那初始Storage Memory分区就有1423.5M。
这意味着如果我们用Spark cache并且executor上缓存的数据量至少达到初始的Storage Memory大小,那么storage分区大小就会保持至少初始大小,因为我们无法从Storage Memory中清除内存块并使之变小。然而如果填满了Storage Memory分区之前Execution Memory分区就增长超过了其初始大小,你不能强行从Execution Memory中清除内存,那么最后执行Memory占用Storgae Memory内存,Storage Memory就会比初始大小要小。